library(tidyverse)
dados <- read.csv("FastFoodNutritionMenuV2.csv") %>%
filter(Company != "Wendy’s" & Company != "Taco Bell")
glimpse(dados)Rows: 811
Columns: 14
$ Company <chr> "McDonald’s", "McDonald’s", "McDonald’s", "McDona…
$ Item <chr> "Hamburger", "Cheeseburger", "Double Cheeseburger…
$ Calories <chr> "250", "300", "440", "390", "510", "740", "540", …
$ Calories.from.Fat <chr> "80", "110", "210", "170", "230", "380", "260", "…
$ Total.Fat..g. <chr> "9", "12", "23", "19", "26", "42", "29", "24", "2…
$ Saturated.Fat..g. <chr> "3.5", "6", "11", "8", "12", "19", "10", "8", "11…
$ Trans.Fat..g. <chr> "0.5", "0.5", "1.5", "1", "1.5", "2.5", "1.5", "1…
$ Cholesterol..mg. <chr> "25", "40", "80", "65", "90", "155", "75", "70", …
$ Sodium...mg. <chr> "520", "750", "1150", "920", "1190", "1380", "104…
$ Carbs..g. <chr> "31", "33", "34", "33", "40", "40", "45", "37", "…
$ Fiber..g. <chr> "2", "2", "2", "2", "3", "3", "3", "3", "3", "4",…
$ Sugars..g. <chr> "6", "6", "7", "7", "9", "9", "9", "8", "8", "13"…
$ Protein..g. <chr> "12", "15", "25", "22", "29", "48", "25", "24", "…
$ Weight.Watchers.Pnts <chr> "247.5", "297", "433", "383", "502", "720", "534"…# Converter colunas de texto para fator e colunas nutricionais para numérico
dados <- dados %>%
mutate(across(c(Company, Item), ~as.factor(.))) %>%
mutate(across(c(Calories,
Calories.from.Fat,
Total.Fat..g.,
Saturated.Fat..g.,
Trans.Fat..g.,
Cholesterol..mg.,
Sodium...mg.,
Carbs..g.,
Fiber..g.,
Sugars..g.,
Protein..g.,
Weight.Watchers.Pnts),
~as.numeric(.)))
glimpse(dados)Rows: 811
Columns: 14
$ Company <fct> McDonald’s, McDonald’s, McDonald’s, McDonald’s, M…
$ Item <fct> "Hamburger", "Cheeseburger", "Double Cheeseburger…
$ Calories <dbl> 250, 300, 440, 390, 510, 740, 540, 460, 510, 790,…
$ Calories.from.Fat <dbl> 80, 110, 210, 170, 230, 380, 260, 220, 250, 350, …
$ Total.Fat..g. <dbl> 9, 12, 23, 19, 26, 42, 29, 24, 28, 39, 39, 40, 18…
$ Saturated.Fat..g. <dbl> 3.5, 6.0, 11.0, 8.0, 12.0, 19.0, 10.0, 8.0, 11.0,…
$ Trans.Fat..g. <dbl> 0.5, 0.5, 1.5, 1.0, 1.5, 2.5, 1.5, 1.5, 1.5, 2.0,…
$ Cholesterol..mg. <dbl> 25, 40, 80, 65, 90, 155, 75, 70, 85, 145, 135, 13…
$ Sodium...mg. <dbl> 520, 750, 1150, 920, 1190, 1380, 1040, 720, 960, …
$ Carbs..g. <dbl> 31, 33, 34, 33, 40, 40, 45, 37, 38, 63, 61, 59, 3…
$ Fiber..g. <dbl> 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 2, 2, 3, 4, 3…
$ Sugars..g. <dbl> 6, 6, 7, 7, 9, 9, 9, 8, 8, 13, 10, 8, 5, 5, 11, 8…
$ Protein..g. <dbl> 12, 15, 25, 22, 29, 48, 25, 24, 27, 45, 40, 44, 1…
$ Weight.Watchers.Pnts <dbl> 247.5, 297.0, 433.0, 383.0, 502.0, 720.0, 534.0, …summary(dados) Company Item Calories Calories.from.Fat
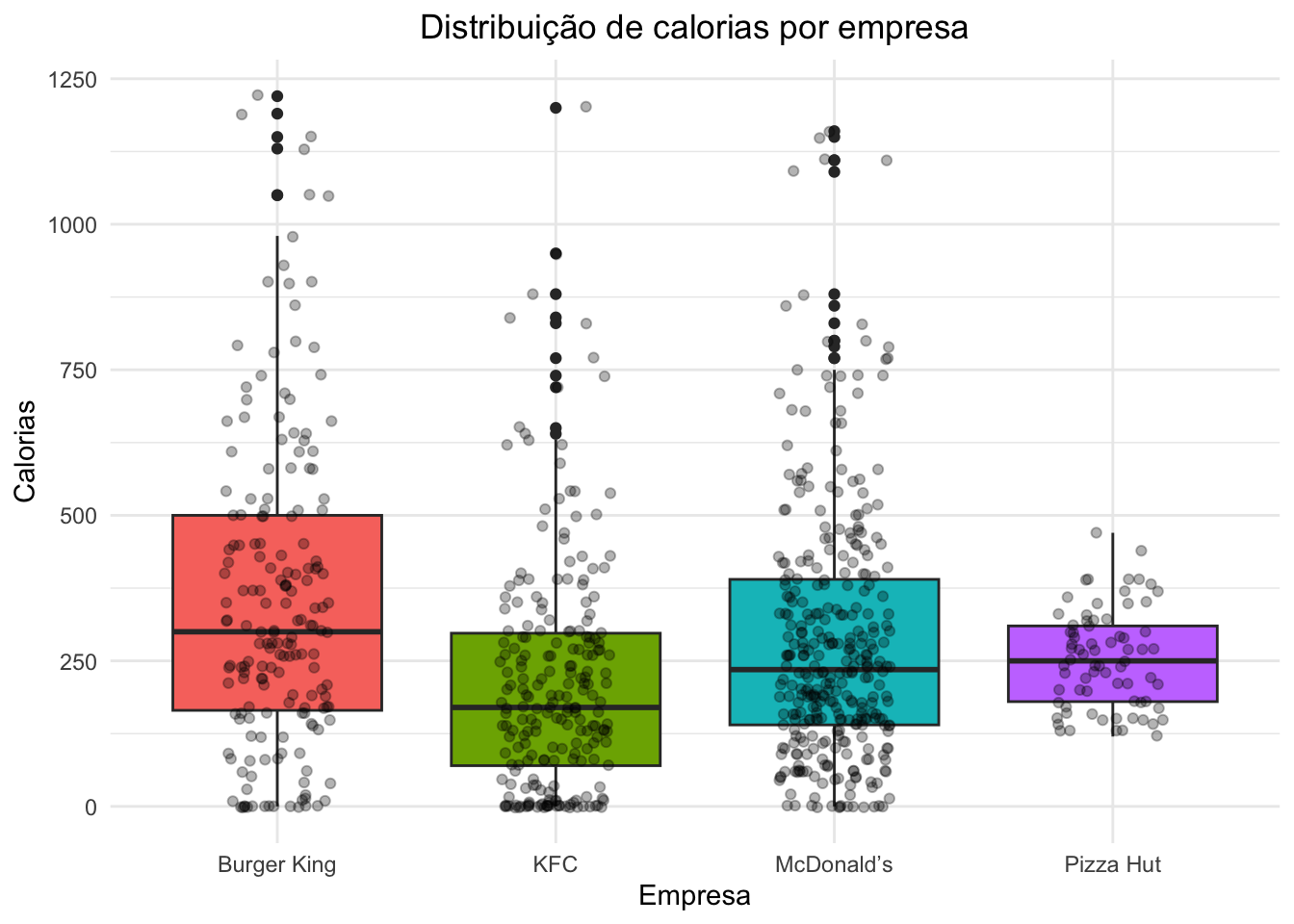
Burger King:190 20 fl oz : 11 Min. : 0.0 Min. : 0.0
KFC :218 29 fl oz : 11 1st Qu.: 130.0 1st Qu.: 0.0
McDonald’s :329 16 fl oz : 9 Median : 240.0 Median : 70.0
Pizza Hut : 74 38 fl oz : 9 Mean : 279.5 Mean :110.2
Cheeseburger: 3 3rd Qu.: 380.0 3rd Qu.:170.0
Hamburger : 3 Max. :1220.0 Max. :750.0
(Other) :765 NA's :12 NA's :307
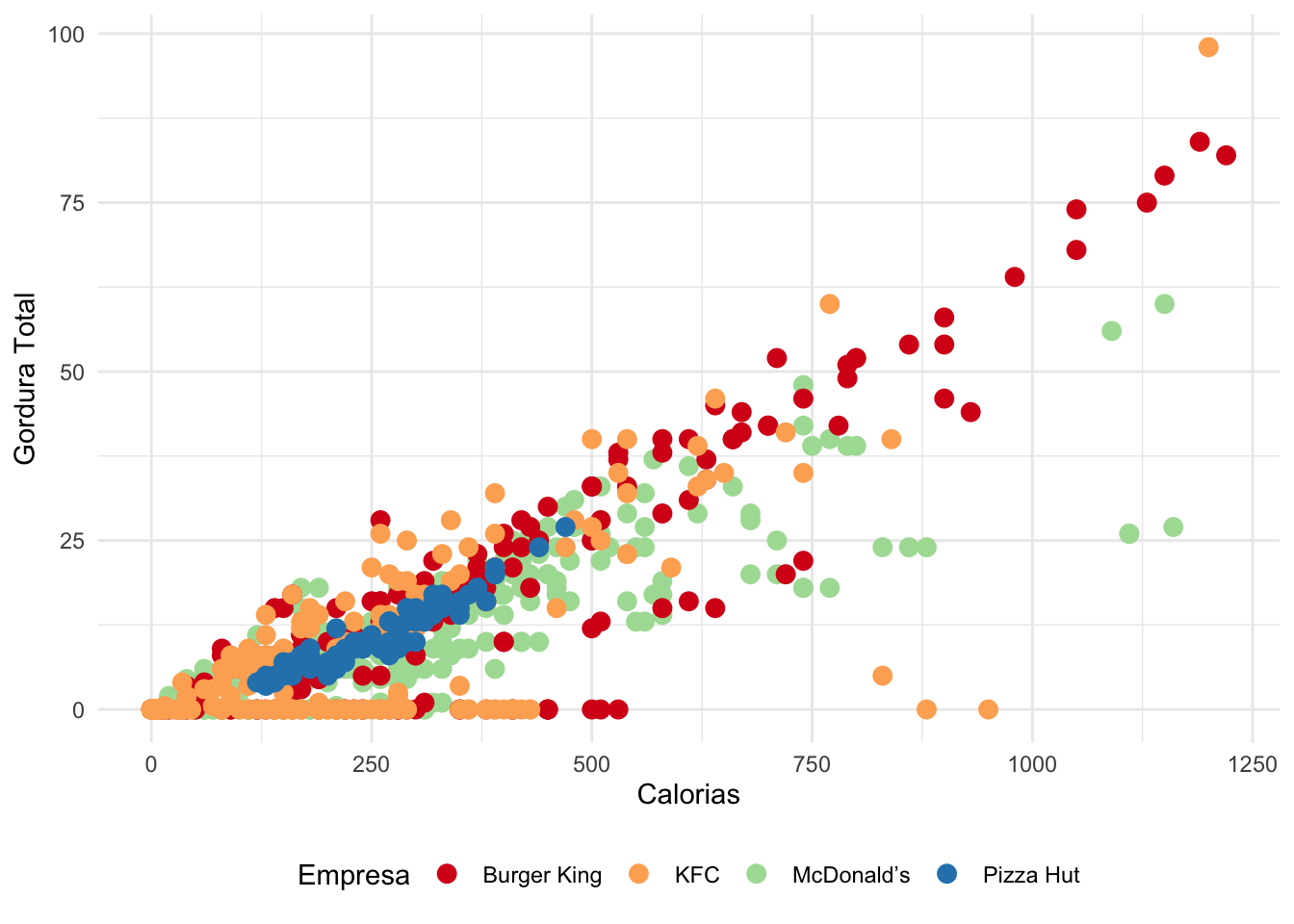
Total.Fat..g. Saturated.Fat..g. Trans.Fat..g. Cholesterol..mg.
Min. : 0.00 Min. : 0.000 Min. :0.0000 Min. : 0.00
1st Qu.: 0.00 1st Qu.: 0.000 1st Qu.:0.0000 1st Qu.: 0.00
Median : 7.00 Median : 2.500 Median :0.0000 Median : 15.00
Mean :10.88 Mean : 3.885 Mean :0.1452 Mean : 35.59
3rd Qu.:16.00 3rd Qu.: 6.000 3rd Qu.:0.0000 3rd Qu.: 40.00
Max. :98.00 Max. :33.000 Max. :4.5000 Max. :575.00
NA's :12 NA's :13 NA's :12 NA's :19
Sodium...mg. Carbs..g. Fiber..g. Sugars..g.
Min. : 0.0 Min. : 0.0 Min. : 0.000 Min. : 0.00
1st Qu.: 85.0 1st Qu.: 15.0 1st Qu.: 0.000 1st Qu.: 2.00
Median : 180.0 Median : 32.0 Median : 0.000 Median : 10.00
Mean : 409.3 Mean : 37.8 Mean : 1.043 Mean : 24.54
3rd Qu.: 580.0 3rd Qu.: 50.0 3rd Qu.: 2.000 3rd Qu.: 40.00
Max. :2890.0 Max. :270.0 Max. :31.000 Max. :264.00
NA's :12 NA's :12 NA's :23 NA's :19
Protein..g. Weight.Watchers.Pnts
Min. : 0.000 Min. : 0.0
1st Qu.: 0.000 1st Qu.: 132.4
Median : 6.000 Median : 265.8
Mean : 8.865 Mean : 303.3
3rd Qu.:13.000 3rd Qu.: 411.2
Max. :71.000 Max. :1317.0
NA's :12 NA's :89